一、非浏览器拦截讲解的简介 【不会拦截蜘蛛爬虫】
通过简单的UA 判断是否是爬虫如果你的api 出现异常
。建议你请求APi的时候UA换成百度蜘蛛的爬虫。
如果是伪造的百度蜘蛛UA 不会影响到其他功能的拦截的。
真实的百度爬虫不会拦截。伪造的百度爬虫如果触发恶意行为。一定会拦截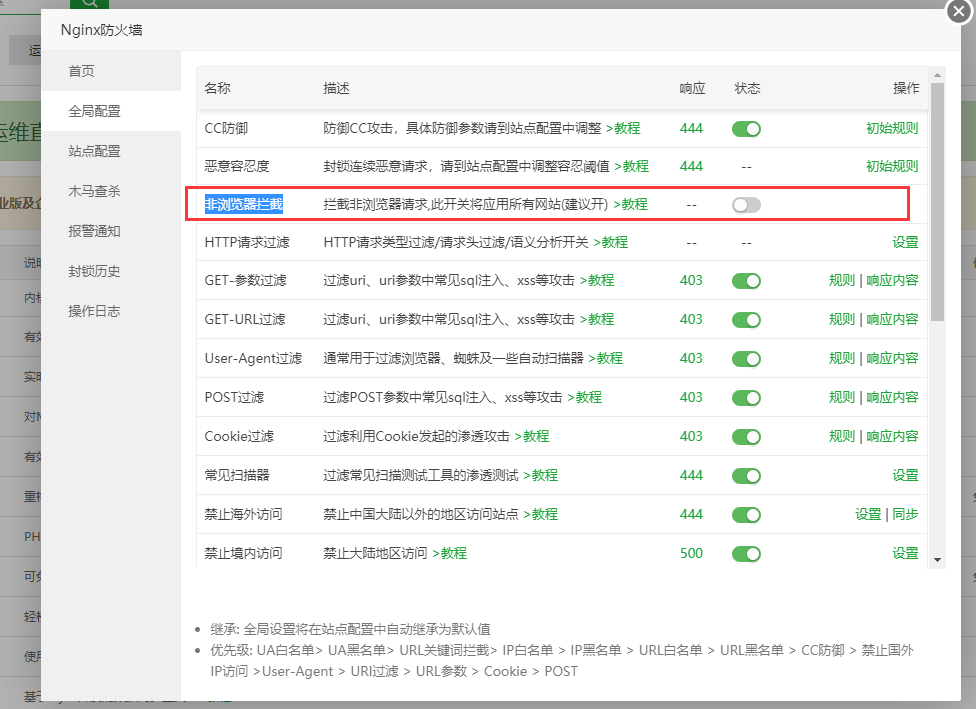
建议开启。此功能。
备注:如果说使用了微信小程序外部调用的话。建议关闭此功能。因为微信那边也是非浏览器的进行验证你的网站的。
一:状态码过滤 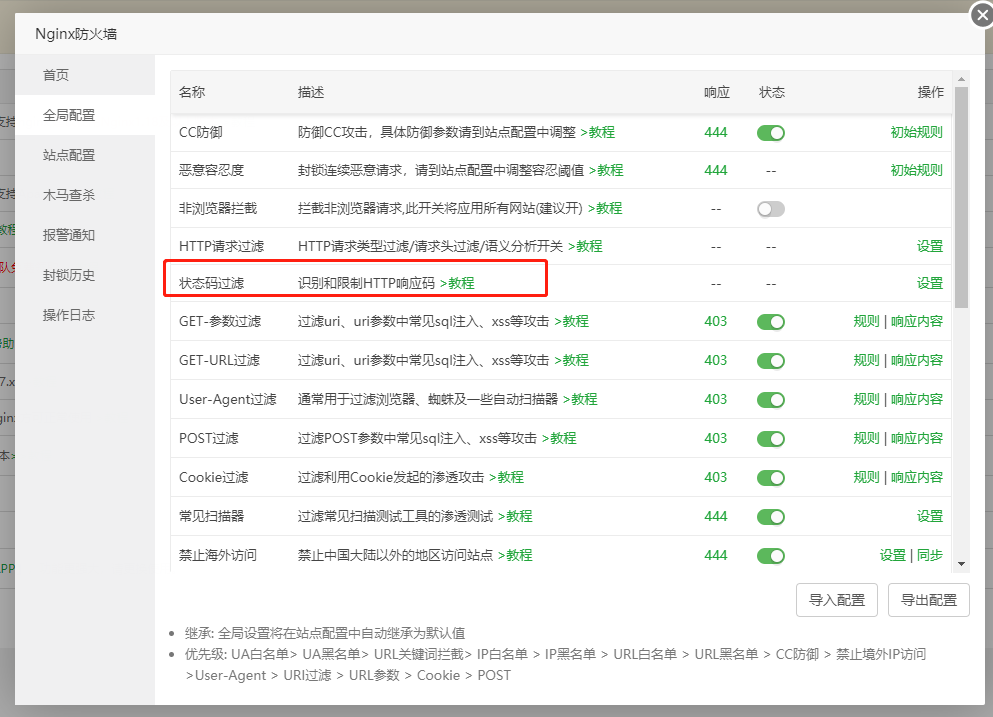
强调一下:这个功能是根据返回的状态码来做一个拦截的。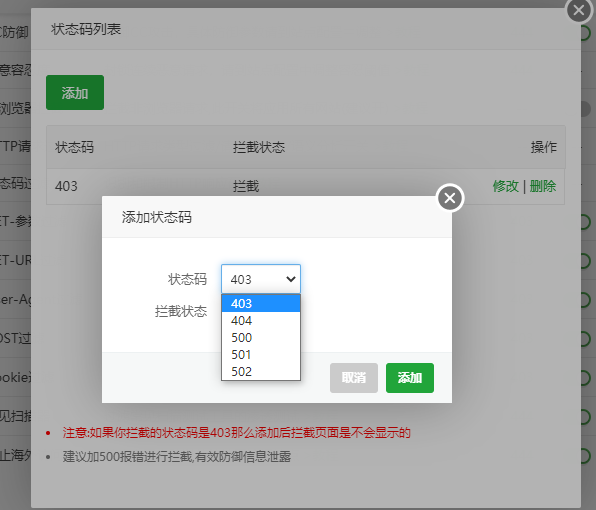
只允许了。状态码为 403 404 500 501 502 这几个状态码能拦截。其他的默认放行。
建议设置500 报错 进行拦截。
因为500 报错中会泄露一些信息。这样有效的保护了信息。
还有一个需要注意的是。如果是你的拦截状态码是403 设置之后。那么防火墙的拦截页面就不会显示了。
二、HTTP请求过滤讲解的简介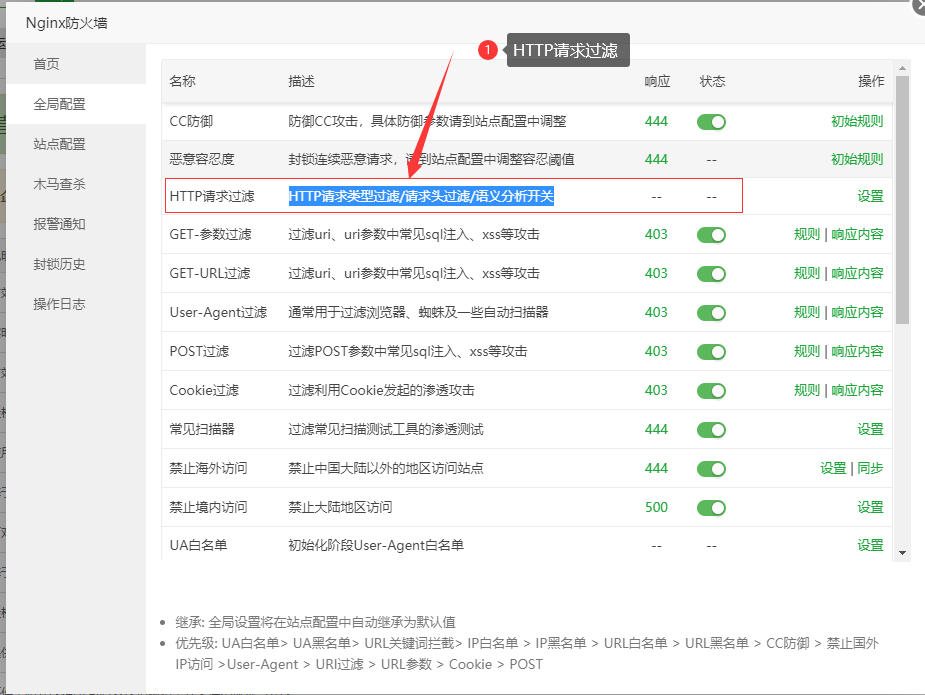
首先说明一下:
1. HTTP请求类型过滤 为请求类型过滤
2. 请求头过滤 为HTTP header 头部长度过滤
3. 语义分析开关 为全局控制开关
二、防御设置
2.1 HTTP请求类型过滤(默认即可)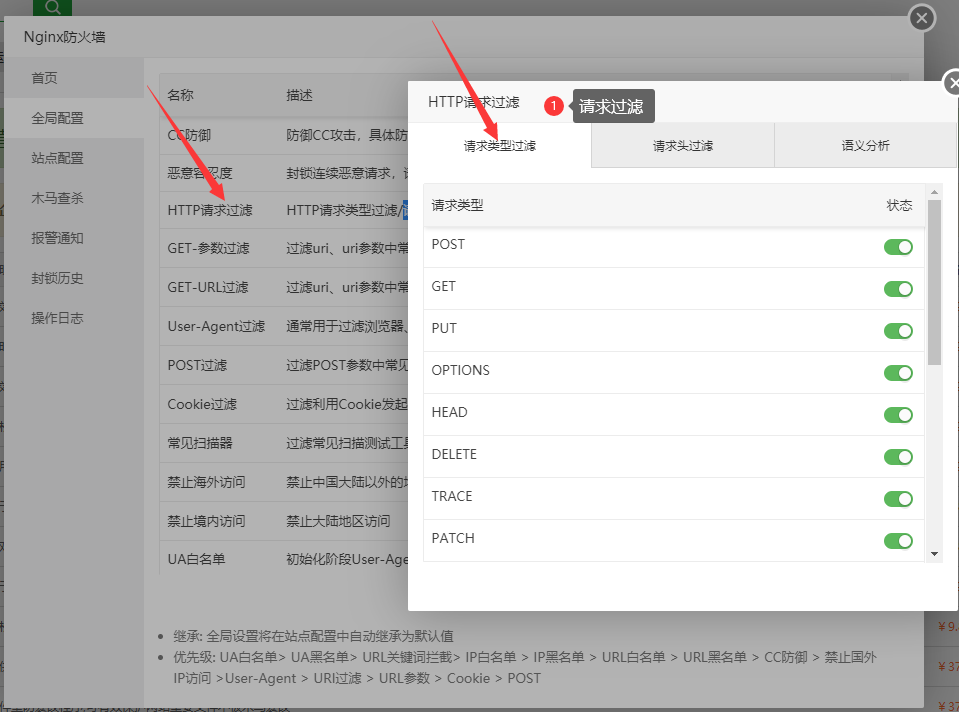
如果你不是很懂这块的话。建议默认就行了。
如果你的需求 只允许POST 和GET 那么你把 除POST 和GET 的所有类型都关闭。
如下: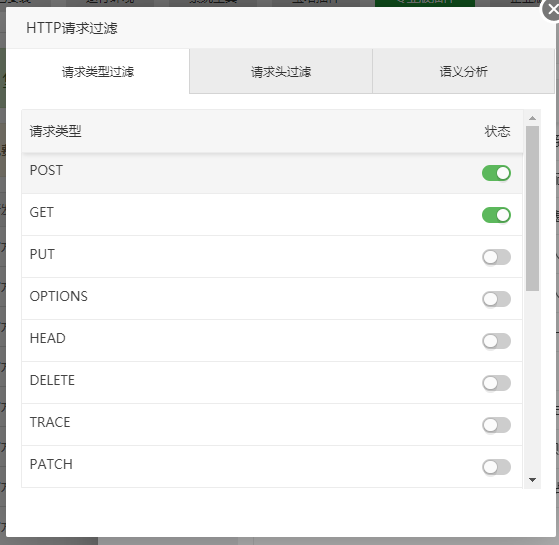
测试。我把GET给关闭了。(记得测试之后开启GET)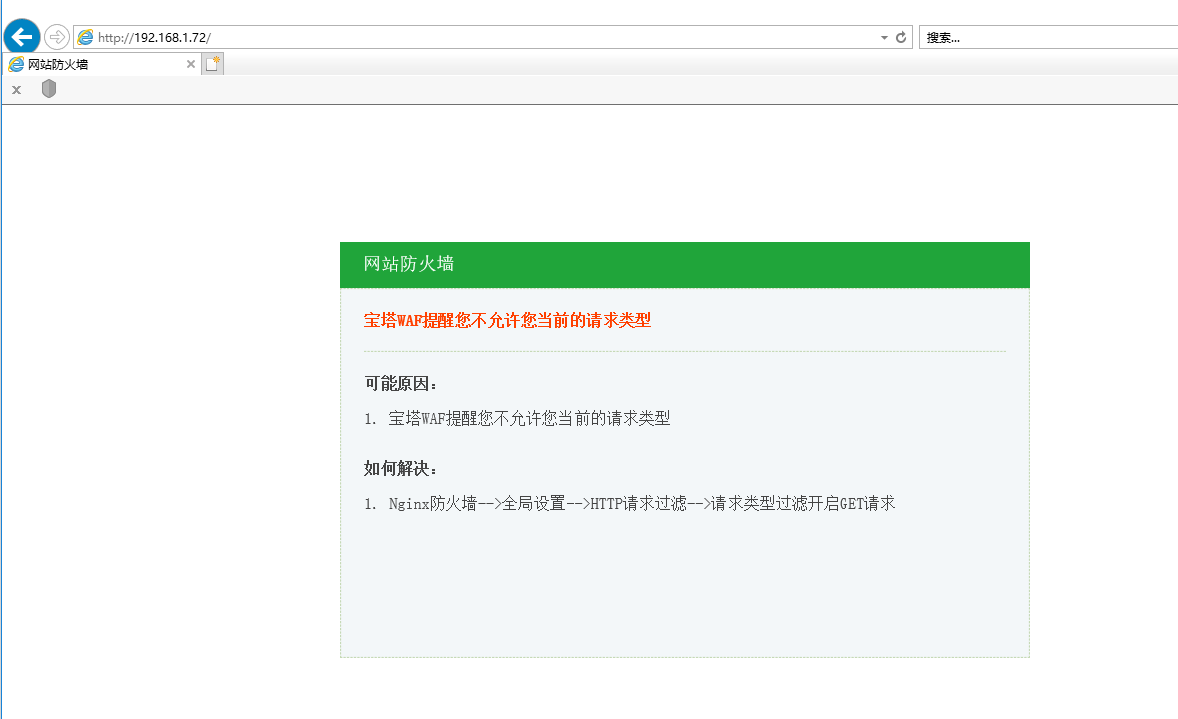
2.2 请求头过滤 (如果没有需求默认即可)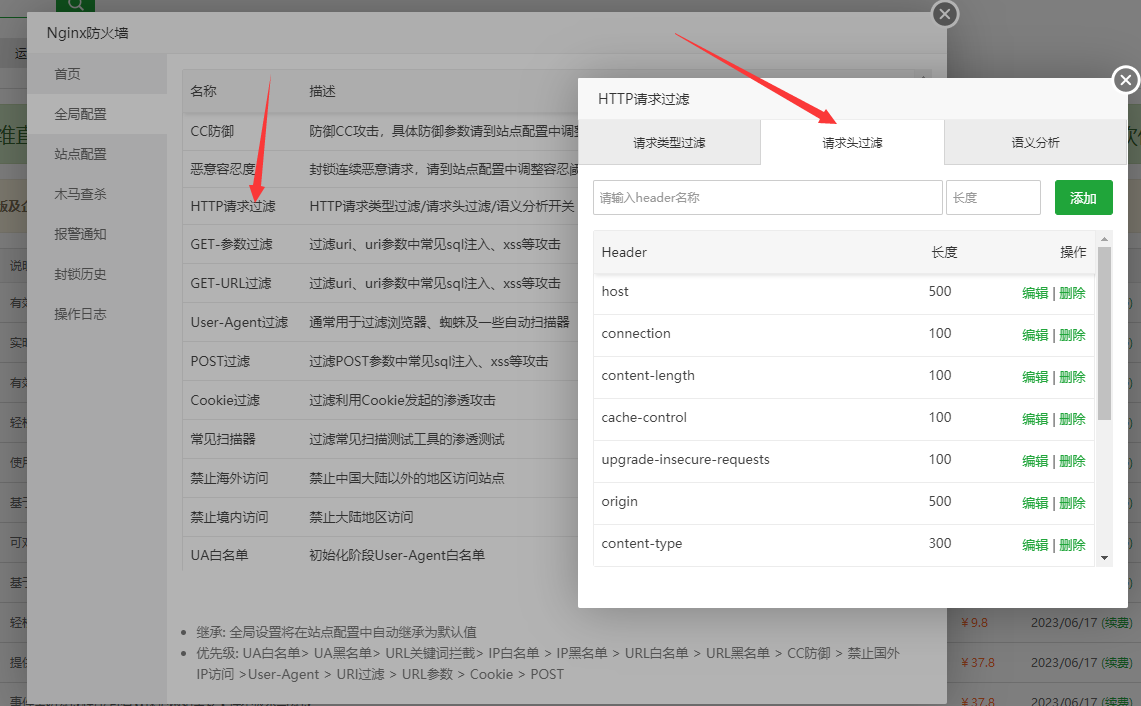
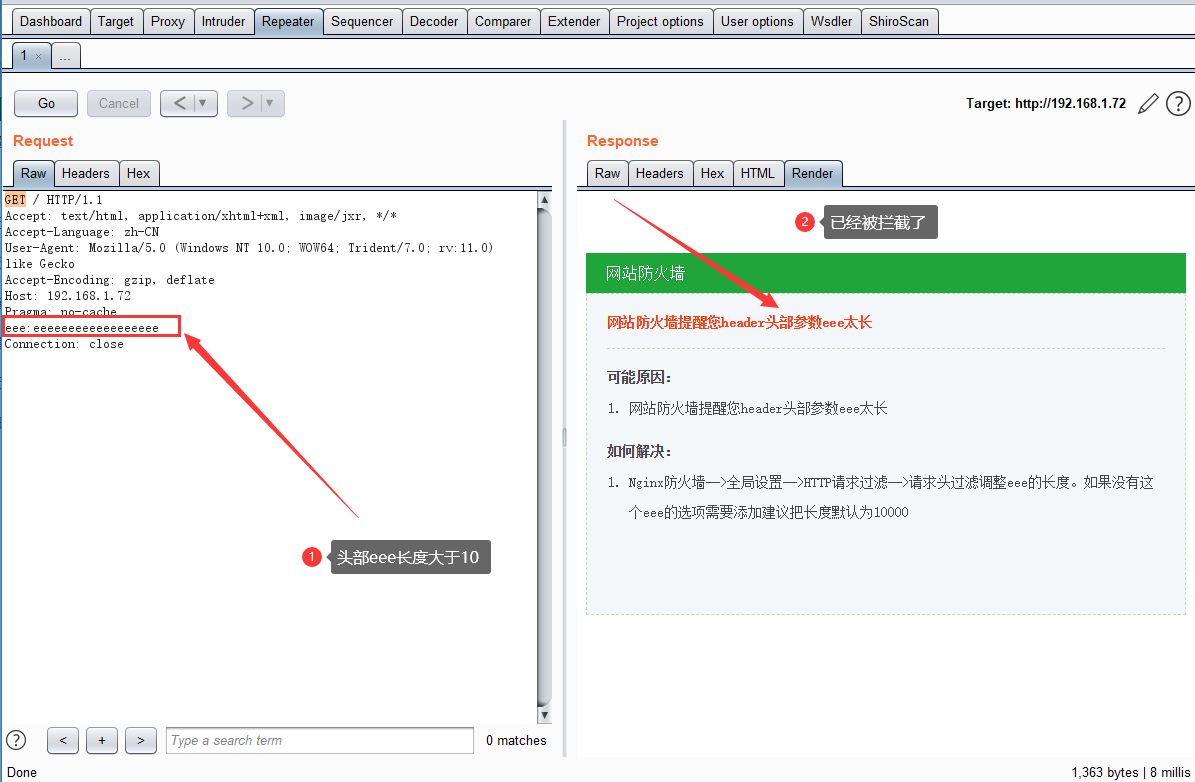
请求头过滤是过滤的请求头的字段长度。
例如(假设) 请求头中的cookie 头部只能500 以内。那么超过这个长度就相当于恶意的请求
测试如下: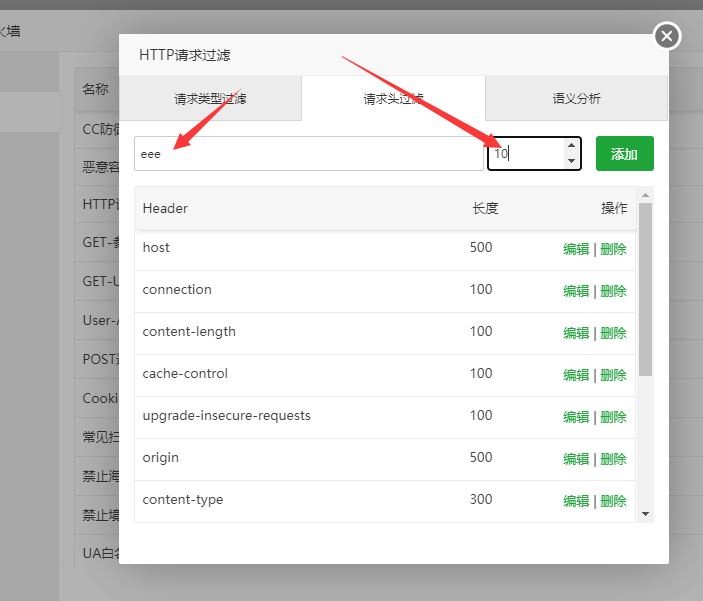
2.3 语义分析开关 (默认即可)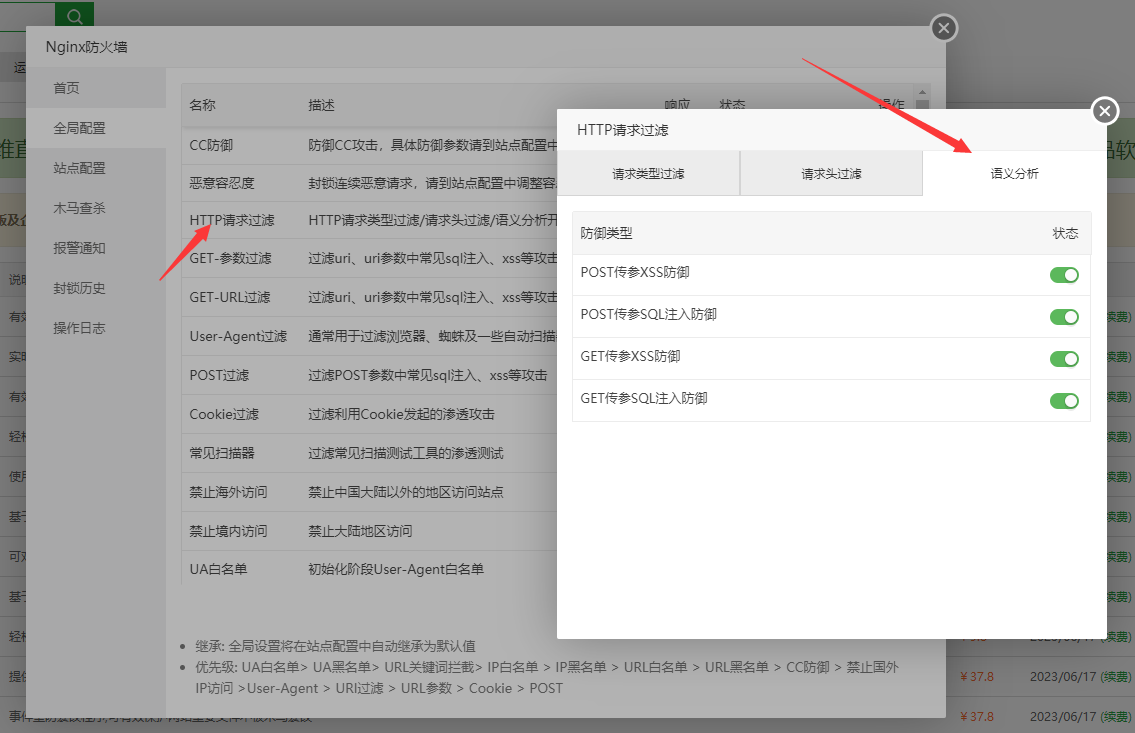
这个是程序内部的语义分析开关。默认不动即可
如果需要测试的话,如下: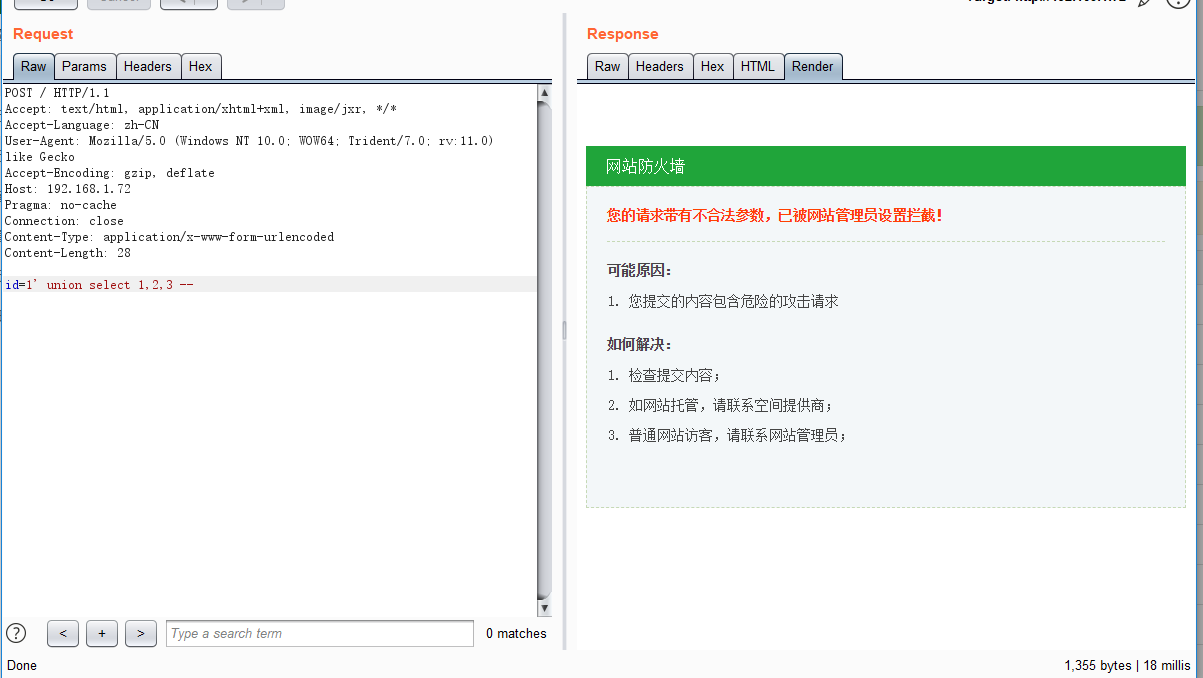
发送一个恶意的SQL 注入请求。然后找到该网站看拦截日志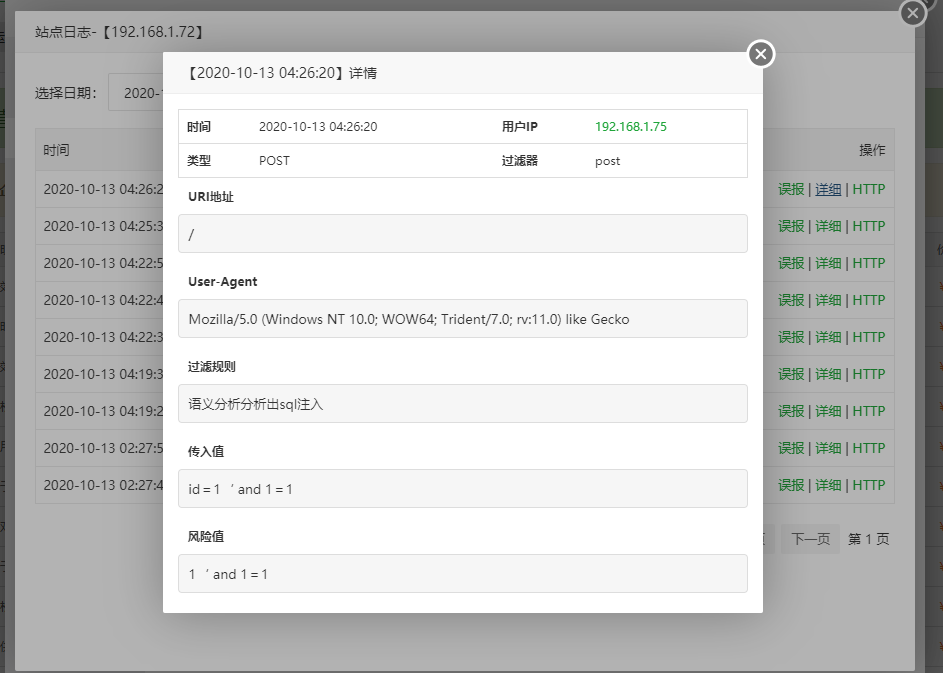
如果没有开启的话。就是内置的那些规则去防护的。
宝塔防火墙HTTP请求过滤讲解
未经允许不得转载:
技术分享-程序员开发基地 »
宝塔防火墙HTTP请求过滤讲解